diff --git a/Readme.md b/Readme.md
index 6b6d8f1..c2a2482 100644
--- a/Readme.md
+++ b/Readme.md
@@ -32,13 +32,23 @@ This is the basic code for fitting SMPL[^loper2015]/SMPL+H[^romero2017]/SMPL-X[^

- Videos are from ZJU-MoCap, with 23 calibrated and synchronized cameras.
+ Videos are from ZJU-MoCap, with 23 calibrated and synchronized cameras.

-
Captured with 8 cameras.
+ Captured with 8 cameras.
+
+
+### Internet video(Coming soon)
+
+This part is the basic code for fitting SMPL[^loper2015] with 2D keypoints estimation[^cao2018,^hrnet] and CNN initialization[^kolotouros2019].
+
+
+

+
+
The raw video is from Youtube.
-

-
Captured with 6 cameras and a mirror
-

-
Internet videos of Roger Federer's serving
+ Internet videos of Roger Federer's serving
### Multiple views of multiple people
@@ -71,21 +77,20 @@ This is the basic code for fitting SMPL[^loper2015]/SMPL+H[^romero2017]/SMPL-X[^

-
Captured with 8 consumer cameras
+ Captured with 8 consumer cameras
### Novel view synthesis from sparse views
[](https://arxiv.org/pdf/2012.15838.pdf) [](https://github.com/zju3dv/neuralbody)
-

-

-
Captured with 8 consumer cameras
+ 
+ Novel view synthesis for chanllenge motion(coming soon)
-
-
Novel view synthesis for chanllenge motion(coming soon)
+ 
+ Novel view synthesis for human interaction(coming soon)

-
LightStage: captured with LightStage system
+ LightStage: captured with LightStage system
-
Mirrored-Human: collected from the Internet
+ Mirrored-Human: collected from the Internet
## Other features
@@ -127,7 +132,7 @@ If you would like to download the ZJU-Mocap dataset, please sign the [agreement]


- Calibration for intrinsic and extrinsic parameters
+ Calibration for intrinsic and extrinsic parameters
### [Annotator](apps/annotation/Readme.md)
@@ -136,7 +141,7 @@ If you would like to download the ZJU-Mocap dataset, please sign the [agreement]
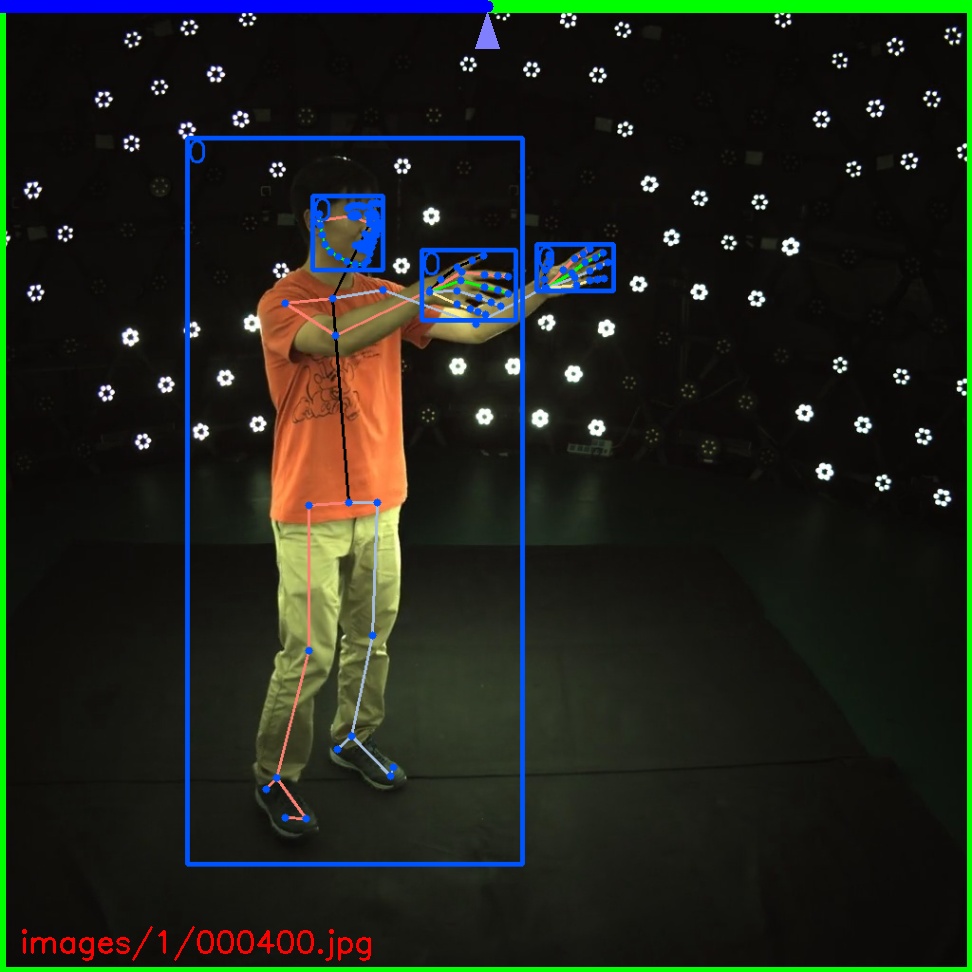

- Annotator for bounding box, keypoints and mask
+ Annotator for bounding box, keypoints and mask
### Other
@@ -232,4 +237,4 @@ Please consider citing these works if you find this repo is useful for your proj
[^bochkovskiy2020]: Bochkovskiy, Alexey, Chien-Yao Wang, and Hong-Yuan Mark Liao. "Yolov4: Optimal speed and accuracy of object detection." arXiv preprint arXiv:2004.10934 (2020).
-
+[^hrnet] Sun, Ke, et al. "Deep high-resolution representation learning for human pose estimation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.