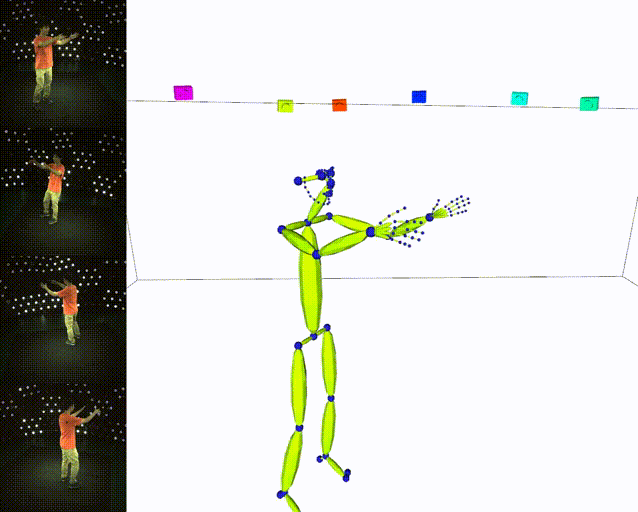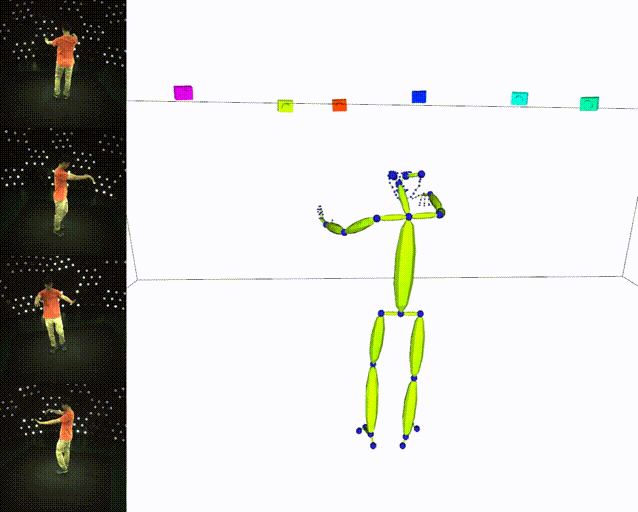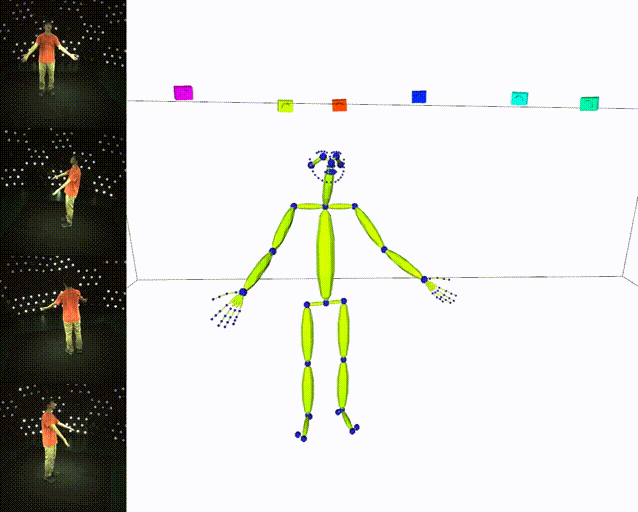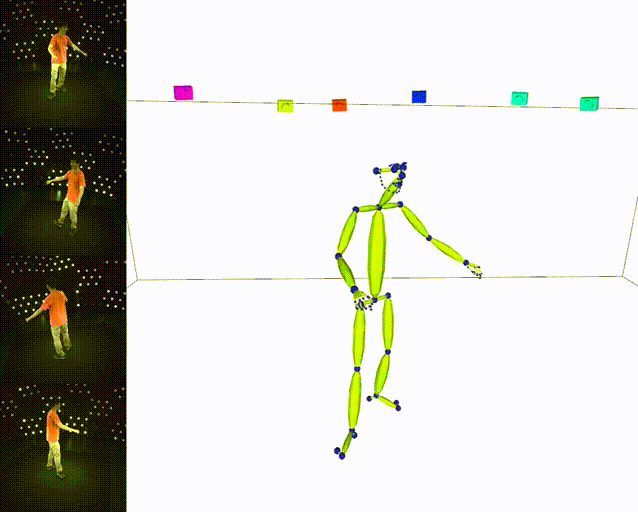# EasyMocap
**EasyMocap** is an open-source toolbox for **markerless human motion capture**.
## Results
|:heavy_check_mark: Skeleton|:heavy_check_mark: SMPL|
|----|----|
|||
> The following features are not released yet. We are now working hard on them. Please stay tuned!
- [ ] Whole body 3d keypoints estimation
- [ ] SMPL-H/SMPLX support
- [ ] Dense reconstruction and view synthesis from sparse view: [Neural Body](https://zju3dv.github.io/neuralbody/).
|:black_square_button: Whole Body|:black_square_button: [Detailed Mesh](https://zju3dv.github.io/neuralbody/)|
|----|----|
|