# EasyMocap
**EasyMocap** is an open-source toolbox for **markerless human motion capture** from RGB videos. In this project, we provide a lot of motion capture demos in different settings.


---
## Core features
### Multiple views of a single person
[](./doc/quickstart.md) [](https://colab.research.google.com/drive/1Cyvu_lPFUajr2RKt6yJIfS3HQIIYl6QU?usp=sharing)
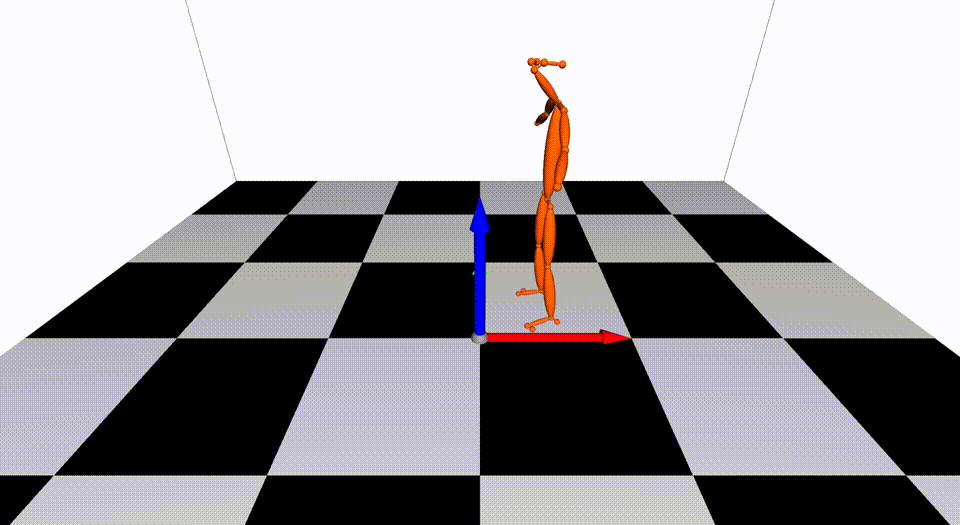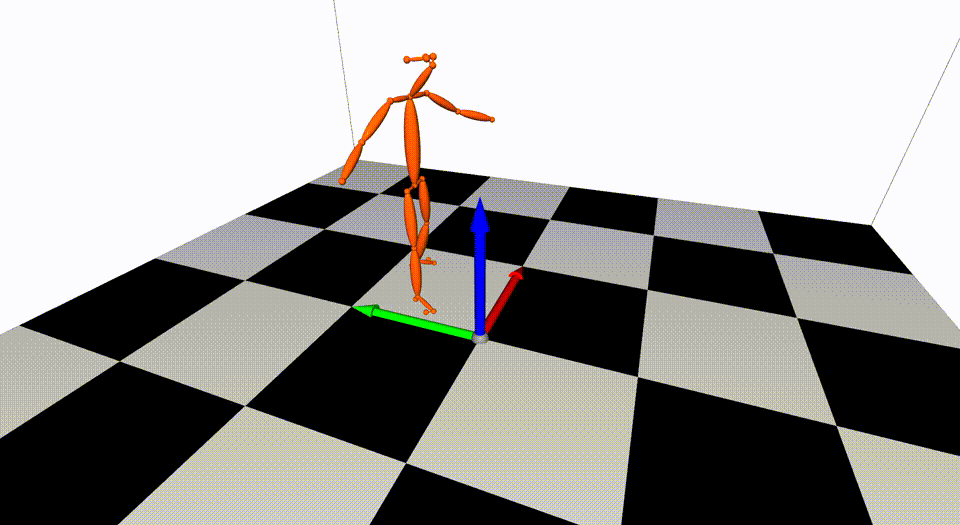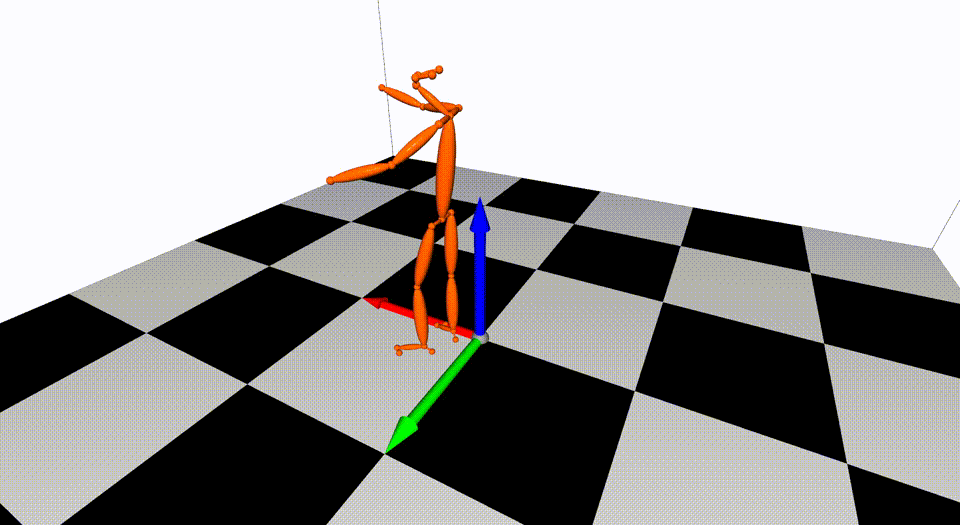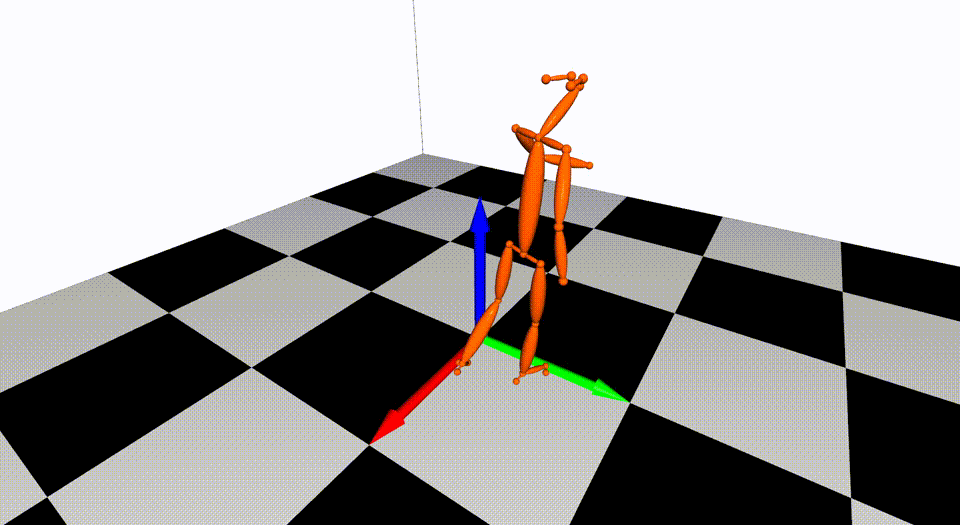
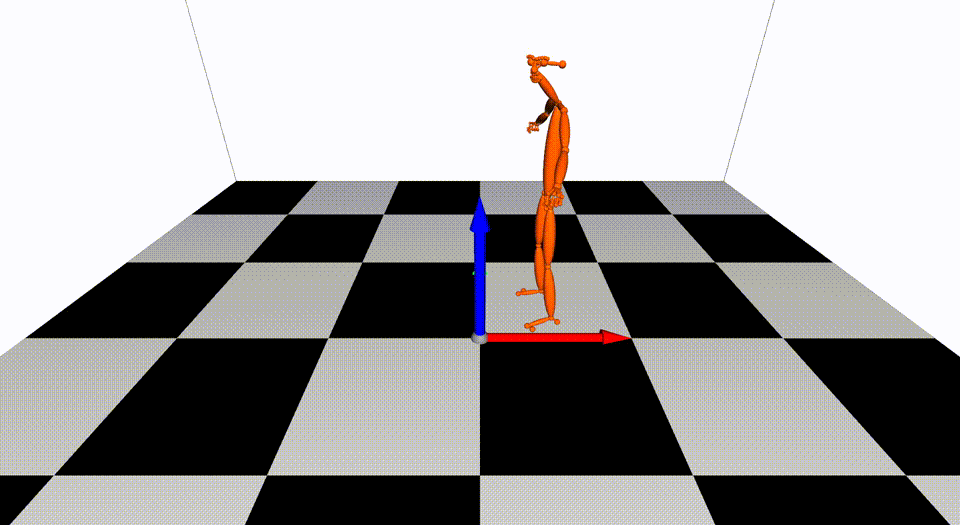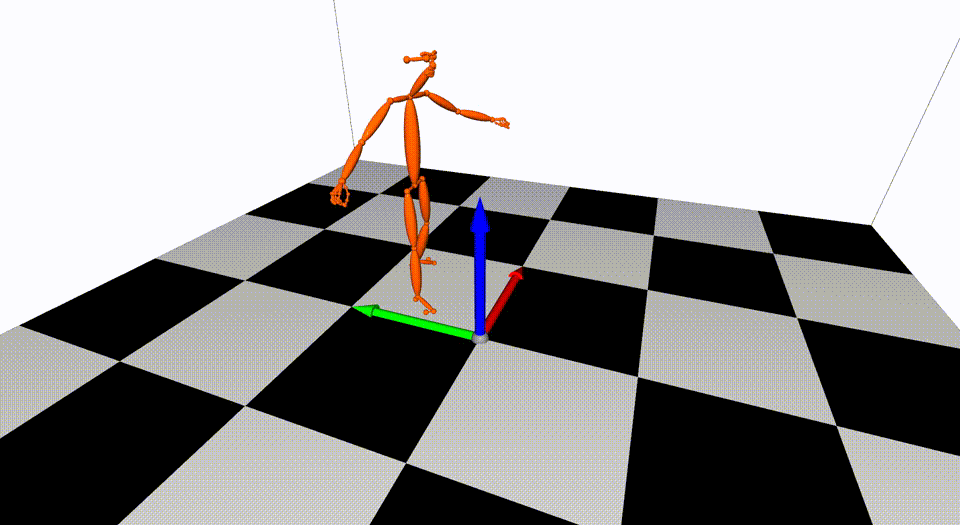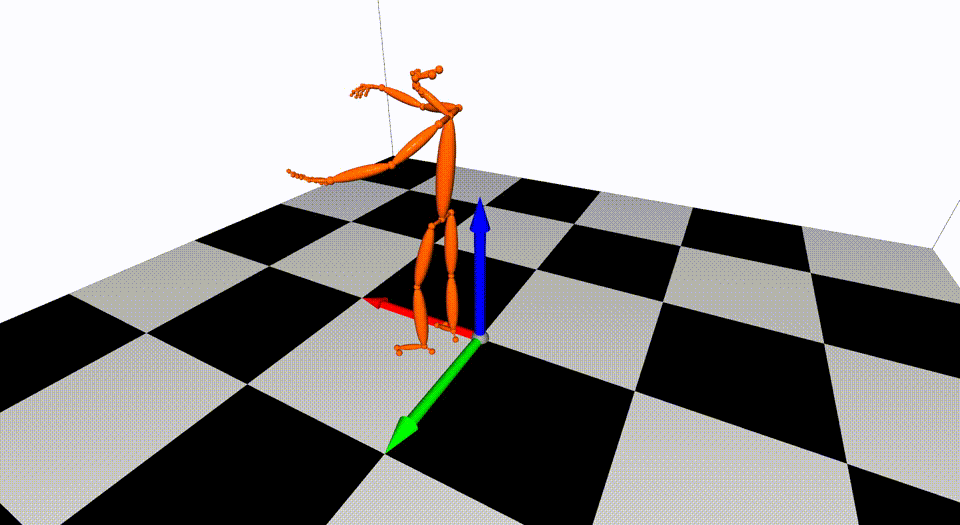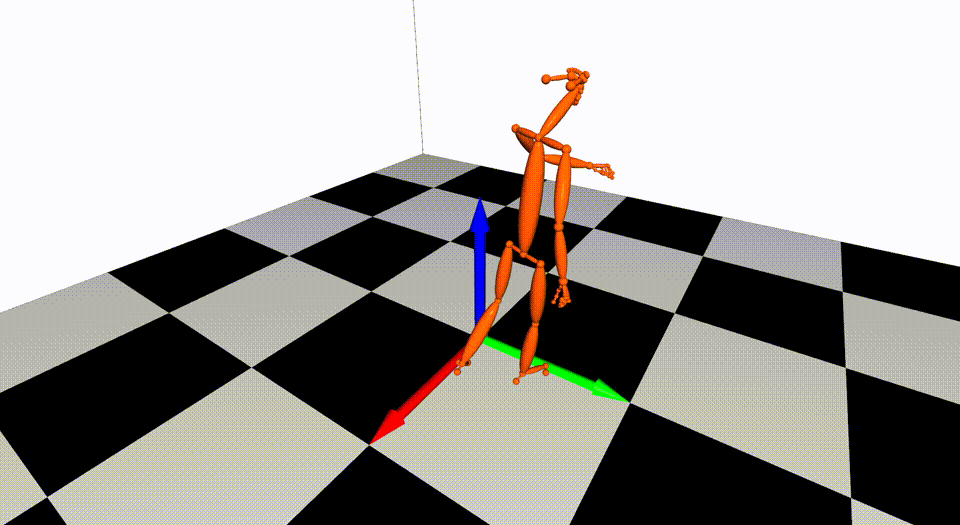
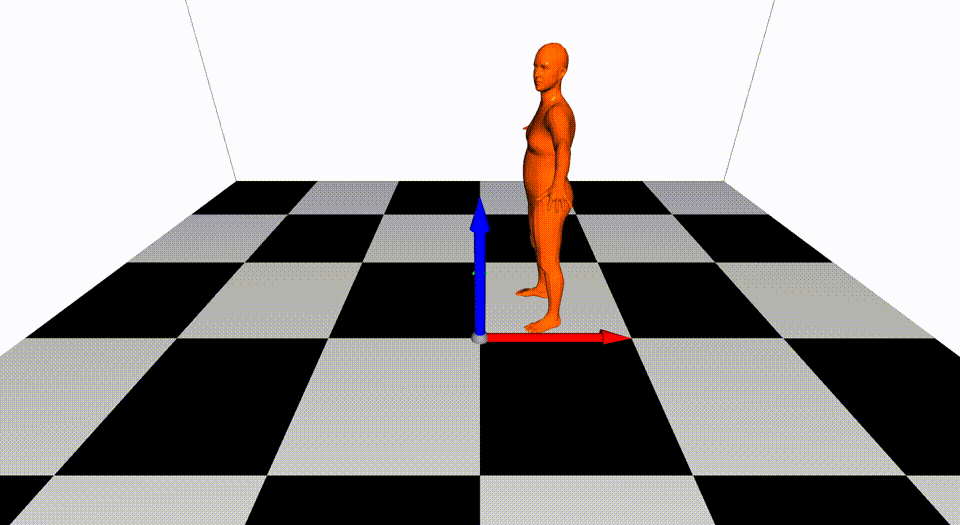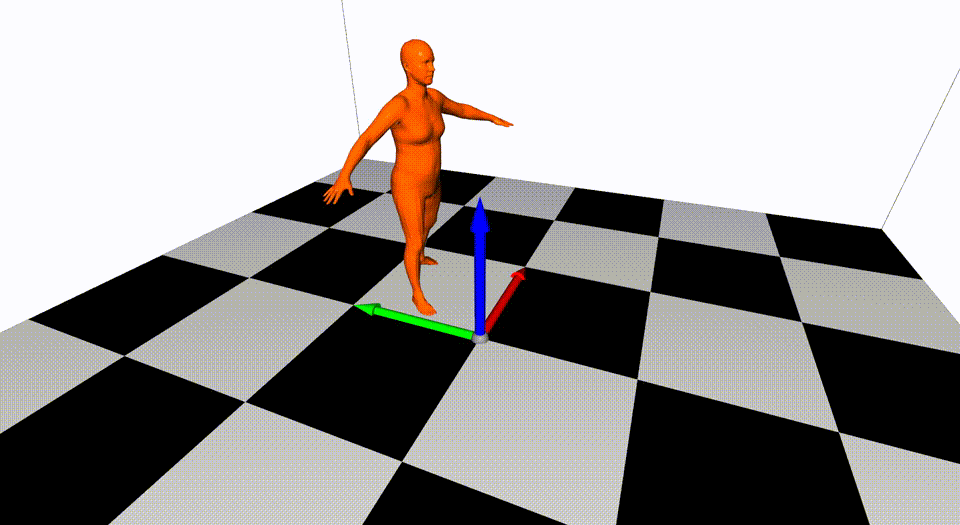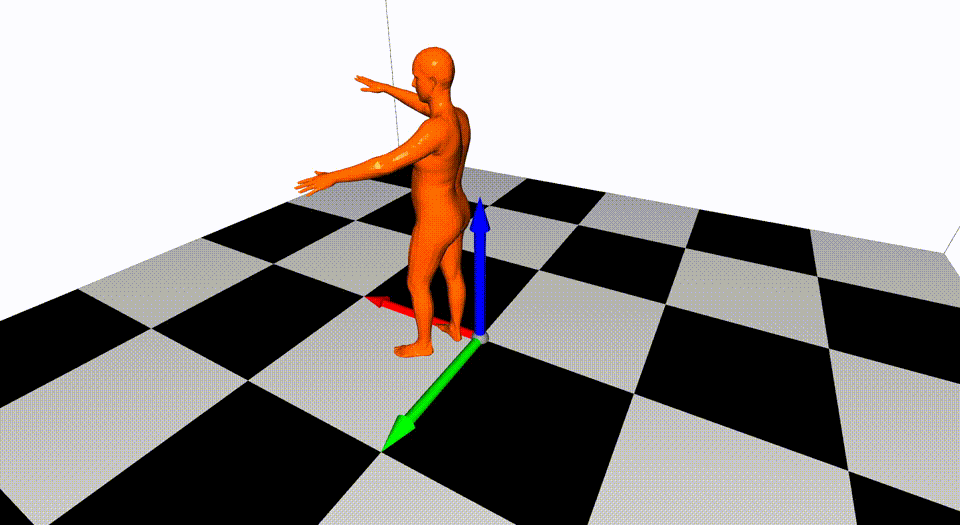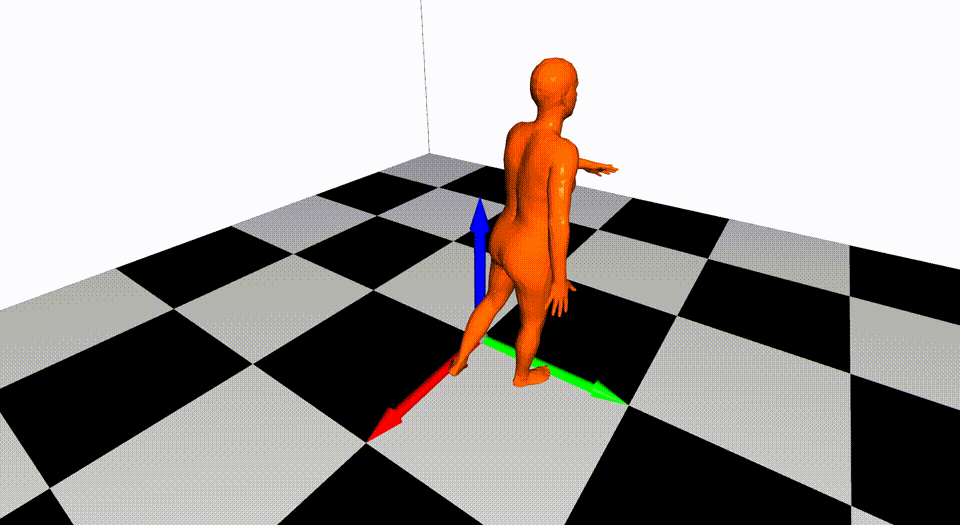
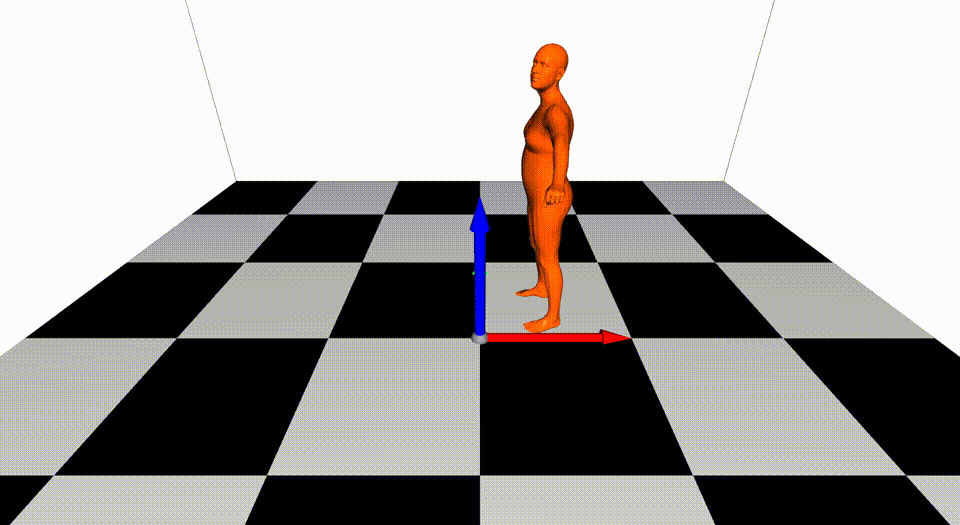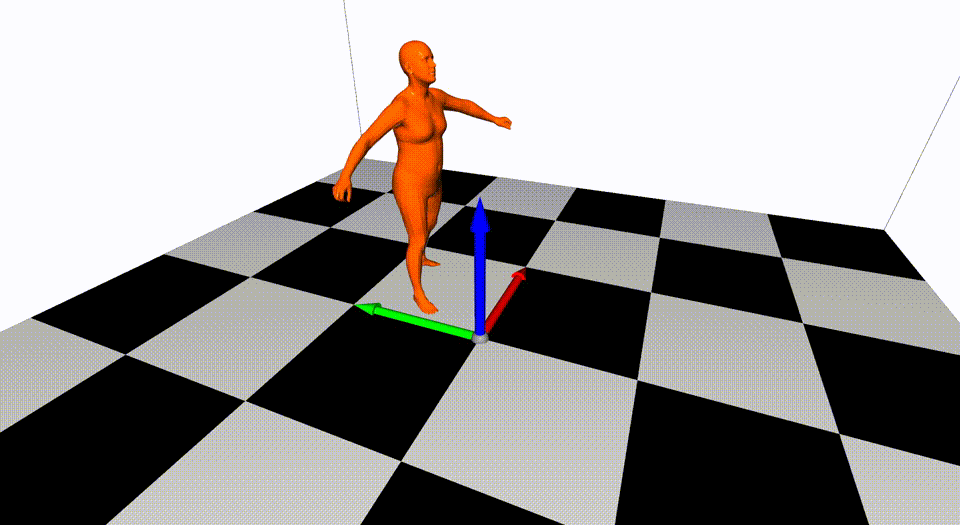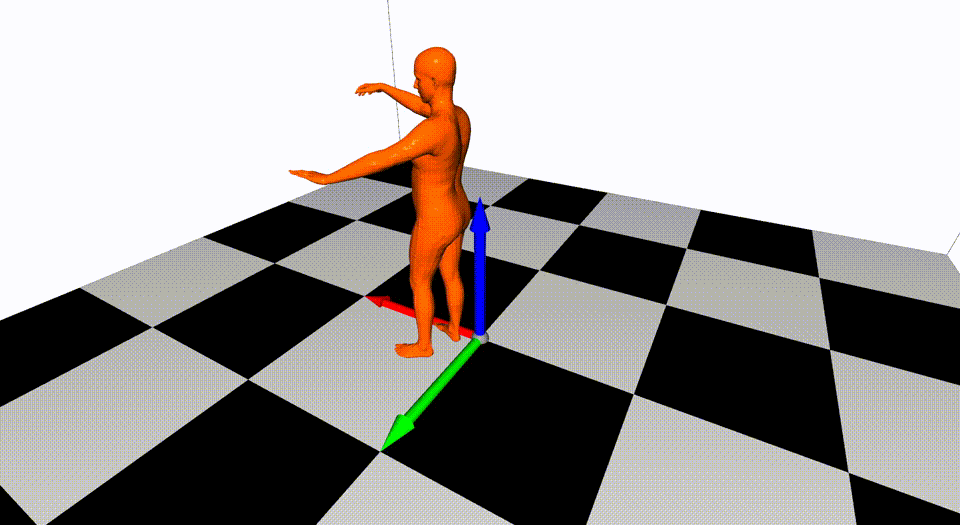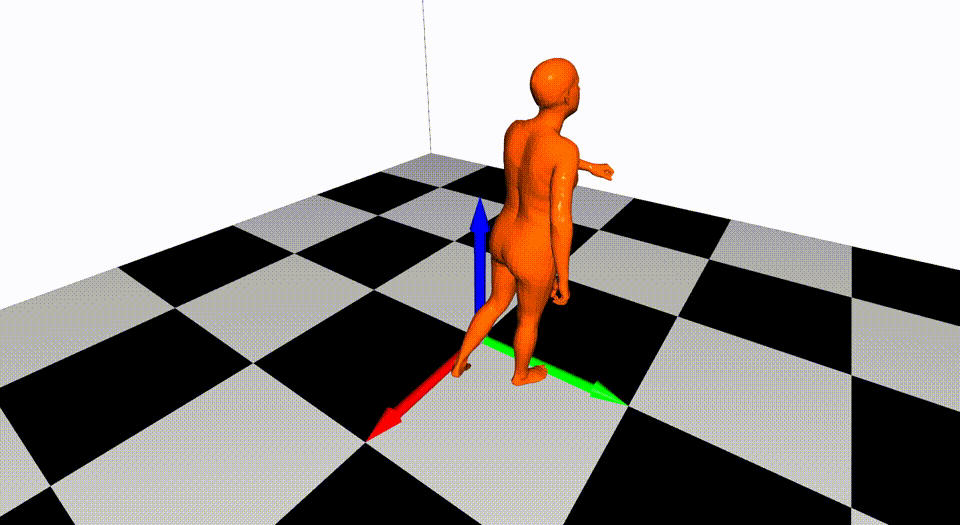
This is the basic code for fitting SMPL[^loper2015]/SMPL+H[^romero2017]/SMPL-X[^pavlakos2019]/MANO[^romero2017] model to capture body+hand+face poses from multiple views.

 Videos are from ZJU-MoCap, with 23 calibrated and synchronized cameras.
Videos are from ZJU-MoCap, with 23 calibrated and synchronized cameras.
 Captured with 8 cameras.
Captured with 8 cameras.
### Internet video(Coming soon)
This part is the basic code for fitting SMPL[^loper2015] with 2D keypoints estimation[^cao2018,^hrnet] and CNN initialization[^kolotouros2019].
### Internet video with a mirror
[](https://arxiv.org/pdf/2104.00340.pdf) [](https://github.com/zju3dv/Mirrored-Human)
### Multiple Internet videos with a specific action (Coming soon)
[](https://arxiv.org/pdf/2008.07931.pdf) [](./doc/todo.md)
 Internet videos of Roger Federer's serving
Internet videos of Roger Federer's serving
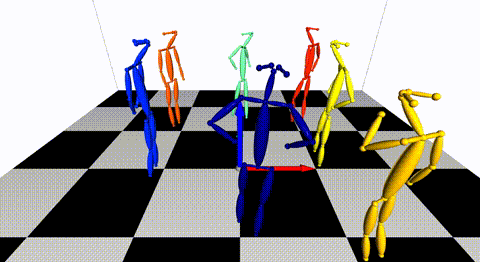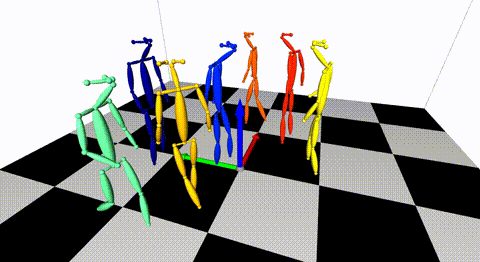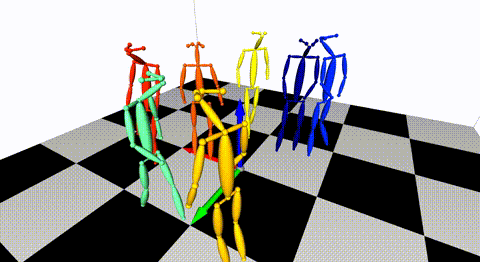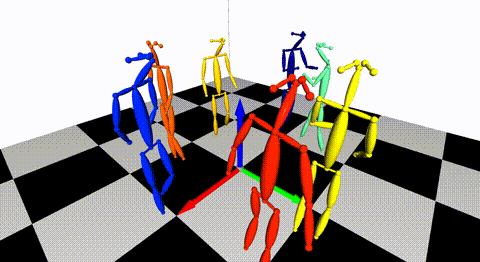
### Multiple views of multiple people
[](https://arxiv.org/pdf/1901.04111.pdf) [](./doc/mvmp.md)
 Captured with 8 consumer cameras
Captured with 8 consumer cameras
### Novel view synthesis from sparse views
[](https://arxiv.org/pdf/2012.15838.pdf) [](https://github.com/zju3dv/neuralbody)
 Novel view synthesis for chanllenge motion(coming soon)
Novel view synthesis for chanllenge motion(coming soon)
 Novel view synthesis for human interaction(coming soon)
Novel view synthesis for human interaction(coming soon)
## ZJU-MoCap
With our proposed method, we release two large dataset of human motion: LightStage and Mirrored-Human. See the [website](https://chingswy.github.io/Dataset-Demo/) for more details.
If you would like to download the ZJU-Mocap dataset, please sign the [agreement](https://zjueducn-my.sharepoint.com/:b:/g/personal/pengsida_zju_edu_cn/EUPiybrcFeNEhdQROx4-LNEBm4lzLxDwkk1SBcNWFgeplA?e=BGDiQh), and email it to Qing Shuai (s_q@zju.edu.cn) and cc Xiaowei Zhou (xwzhou@zju.edu.cn) to request the download link.
 LightStage: captured with LightStage system
LightStage: captured with LightStage system
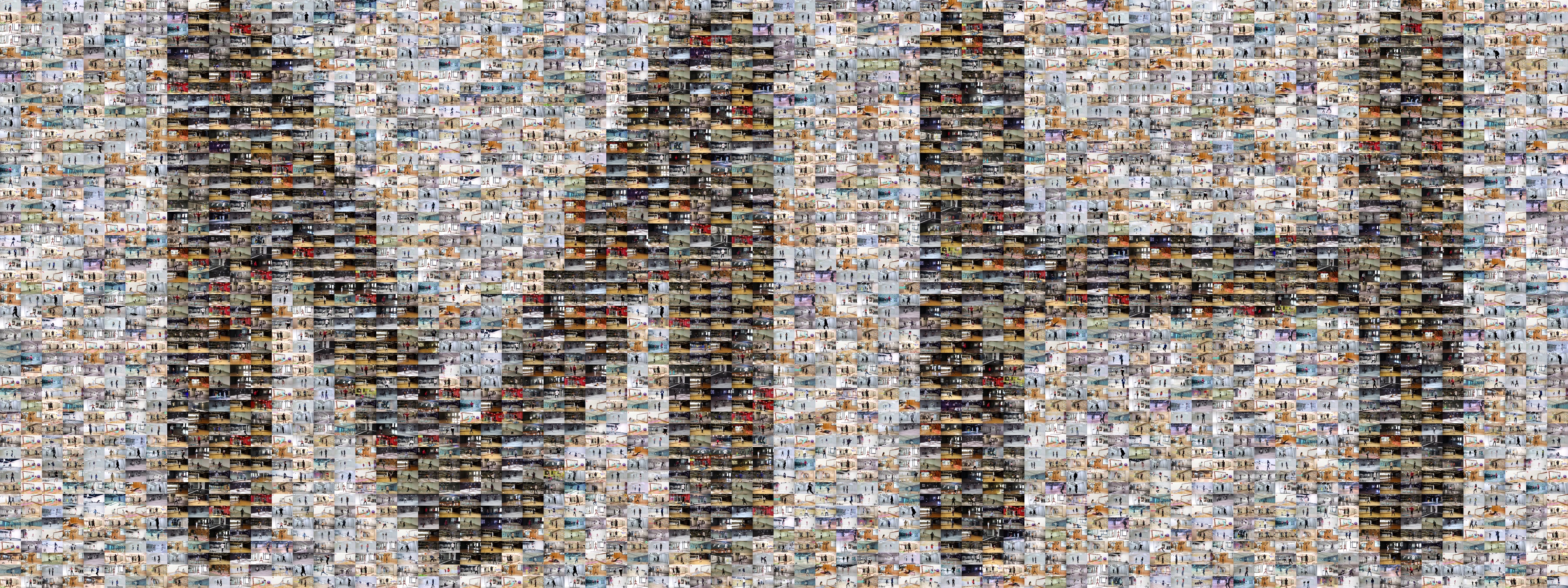 Mirrored-Human: collected from the Internet
Mirrored-Human: collected from the Internet
## Other features
### 3D Realtime visualization
[](./doc/realtime_visualization.md)
### [Camera calibration](apps/calibration/Readme.md)

 Calibration for intrinsic and extrinsic parameters
Calibration for intrinsic and extrinsic parameters
### [Annotator](apps/annotation/Readme.md)
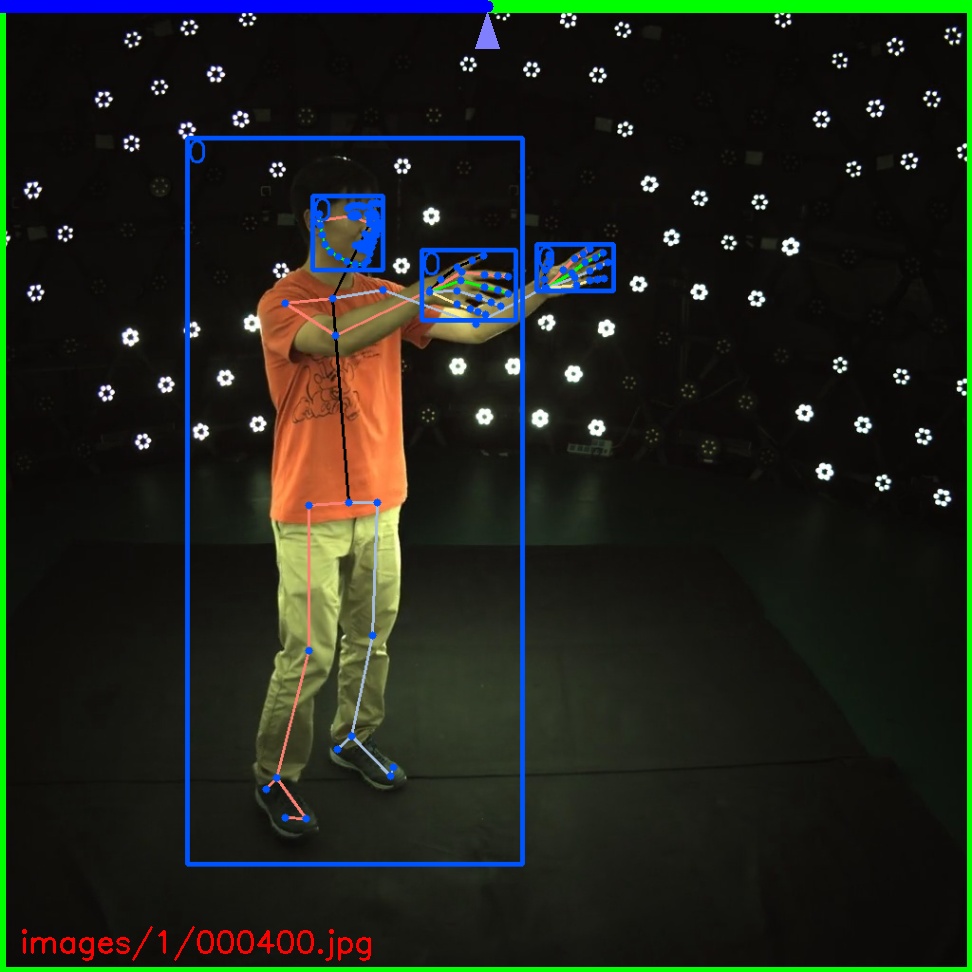
 Annotator for bounding box, keypoints and mask
Annotator for bounding box, keypoints and mask
### Other
- [Pose guided synchronization](./doc/todo.md) (comming soon)
- [Exporting of multiple data formats(bvh, asf/amc, ...)](./doc/02_output.md)
## Updates
- 12/25/2021: Support mediapipe keypoints detector.
- 08/09/2021: Add a colab demo [here](https://colab.research.google.com/drive/1Cyvu_lPFUajr2RKt6yJIfS3HQIIYl6QU?usp=sharing).
- 06/28/2021: The **Multi-view Multi-person** part is released!
- 06/10/2021: The **real-time 3D visualization** part is released!
- 04/11/2021: The calibration tool and the annotator are released.
- 04/11/2021: **Mirrored-Human** part is released.
## Installation
See [doc/install](./doc/installation.md) for more instructions.
## Acknowledgements
Here are the great works this project is built upon:
- SMPL models and layer are from MPII [SMPL-X model](https://github.com/vchoutas/smplx).
- Some functions are borrowed from [SPIN](https://github.com/nkolot/SPIN), [VIBE](https://github.com/mkocabas/VIBE), [SMPLify-X](https://github.com/vchoutas/smplify-x)
- The method for fitting 3D skeleton and SMPL model is similar to [TotalCapture](http://www.cs.cmu.edu/~hanbyulj/totalcapture/), without using point clouds.
- We integrate some easy-to-use functions for previous great work:
- `easymocap/estimator/mediapipe_wrapper.py`: [MediaPipe](https://github.com/google/mediapipe)
- `easymocap/estimator/SPIN` : an SMPL estimator[^cao2018]
- `easymocap/estimator/YOLOv4`: an object detector[^kolotouros2019] (Coming soon)
- `easymocap/estimator/HRNet` : a 2D human pose estimator[^bochkovskiy2020] (Coming soon)
## Contact
Please open an issue if you have any questions. We appreciate all contributions to improve our project.
## Contributor
EasyMocap is **built by** researchers from the 3D vision group of Zhejiang University: [**Qing Shuai**](https://chingswy.github.io/), [**Qi Fang**](https://raypine.github.io/), [**Junting Dong**](https://jtdong.com/), [**Sida Peng**](https://pengsida.net/), **Di Huang**, [**Hujun Bao**](http://www.cad.zju.edu.cn/home/bao/), **and** [**Xiaowei Zhou**](https://xzhou.me/).
We would like to thank Wenduo Feng, Di Huang, Yuji Chen, Hao Xu, Qing Shuai, Qi Fang, Ting Xie, Junting Dong, Sida Peng and Xiaopeng Ji who are the performers in the sample data. We would also like to thank all the people who has helped EasyMocap [in any way](https://github.com/zju3dv/EasyMocap/graphs/contributors).
## Citation
This project is a part of our work [iMocap](https://zju3dv.github.io/iMoCap/), [Mirrored-Human](https://zju3dv.github.io/Mirrored-Human/), [mvpose](https://zju3dv.github.io/mvpose/) and [Neural Body](https://zju3dv.github.io/neuralbody/)
Please consider citing these works if you find this repo is useful for your projects.
```bibtex
@inproceedings{dong2021fast,
title={Fast and Robust Multi-Person 3D Pose Estimation and Tracking from Multiple Views},
author={Dong, Junting and Fang, Qi and Jiang, Wen and Yang, Yurou and Bao, Hujun and Zhou, Xiaowei},
booktitle={T-PAMI},
year={2021}
}
@inproceedings{dong2020motion,
title={Motion capture from internet videos},
author={Dong, Junting and Shuai, Qing and Zhang, Yuanqing and Liu, Xian and Zhou, Xiaowei and Bao, Hujun},
booktitle={European Conference on Computer Vision},
pages={210--227},
year={2020},
organization={Springer}
}
@inproceedings{peng2021neural,
title={Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans},
author={Peng, Sida and Zhang, Yuanqing and Xu, Yinghao and Wang, Qianqian and Shuai, Qing and Bao, Hujun and Zhou, Xiaowei},
booktitle={CVPR},
year={2021}
}
@inproceedings{fang2021mirrored,
title={Reconstructing 3D Human Pose by Watching Humans in the Mirror},
author={Fang, Qi and Shuai, Qing and Dong, Junting and Bao, Hujun and Zhou, Xiaowei},
booktitle={CVPR},
year={2021}
}
```
[^loper2015]: Loper, Matthew, et al. "SMPL: A skinned multi-person linear model." ACM transactions on graphics (TOG) 34.6 (2015): 1-16.
[^romero2017]: Romero, Javier, Dimitrios Tzionas, and Michael J. Black. "Embodied hands: Modeling and capturing hands and bodies together." ACM Transactions on Graphics (ToG) 36.6 (2017): 1-17.
[^pavlakos2019]: Pavlakos, Georgios, et al. "Expressive body capture: 3d hands, face, and body from a single image." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.
[^cao2018]: Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: Openpose: real-time multi-person 2d pose estimation using part affinity fields. arXiv preprint arXiv:1812.08008 (2018)
[^kolotouros2019]: Kolotouros, Nikos, et al. "Learning to reconstruct 3D human pose and shape via model-fitting in the loop." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019
[^bochkovskiy2020]: Bochkovskiy, Alexey, Chien-Yao Wang, and Hong-Yuan Mark Liao. "Yolov4: Optimal speed and accuracy of object detection." arXiv preprint arXiv:2004.10934 (2020).
[^hrnet] Sun, Ke, et al. "Deep high-resolution representation learning for human pose estimation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.