| code | ||
| data/smplx | ||
| doc | ||
| scripts | ||
| .gitignore | ||
| LICENSE | ||
| Readme.md | ||
| requirements.txt | ||
EasyMocap
EasyMocap is an open-source toolbox for markerless human motion capture.
Results
| ✔️ Skeleton | ✔️ SMPL |
|---|---|
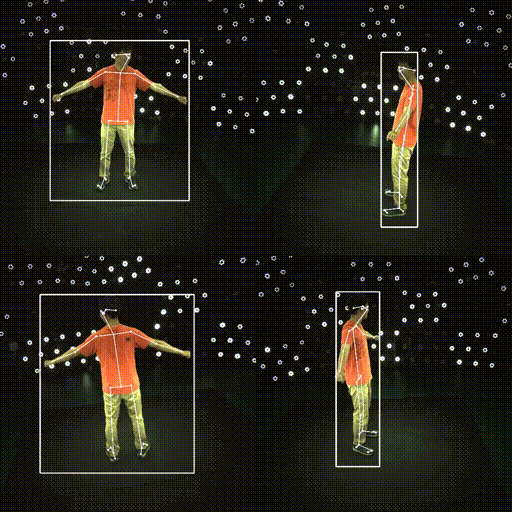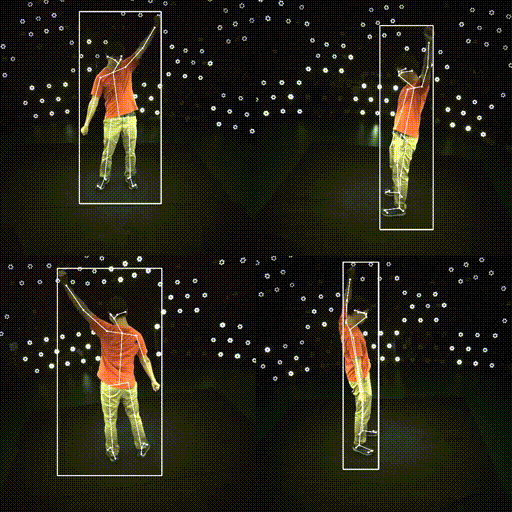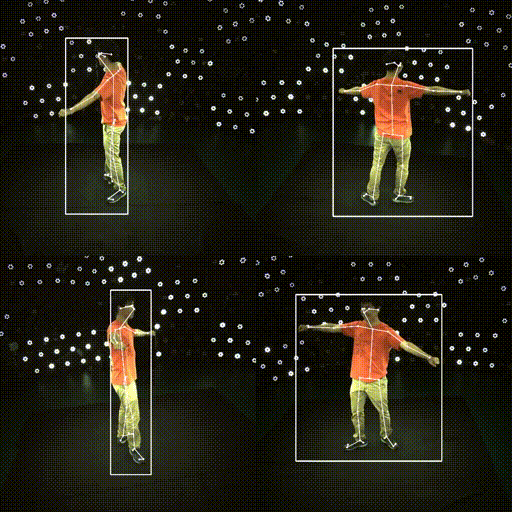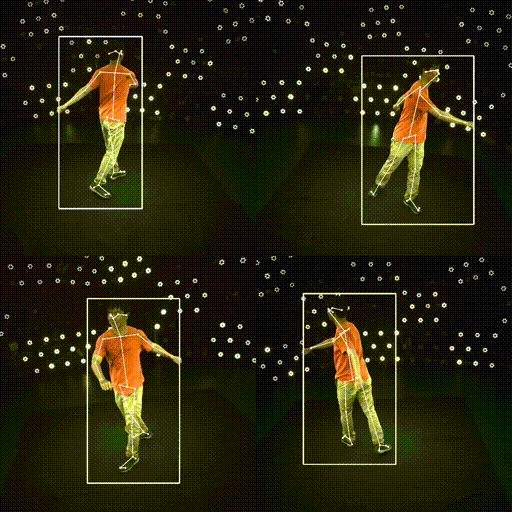 |
 |
The following codes are not released. We are now working hard on them.
- Whole body 3d keypoints estimation
- SMPL-H/SMPLX support
- Detailed mesh from sparse view. An alternative way to obtain detailed mesh is using Neural Body.
| 🔲 Whole Body | 🔲 Detailed Mesh |
|---|---|
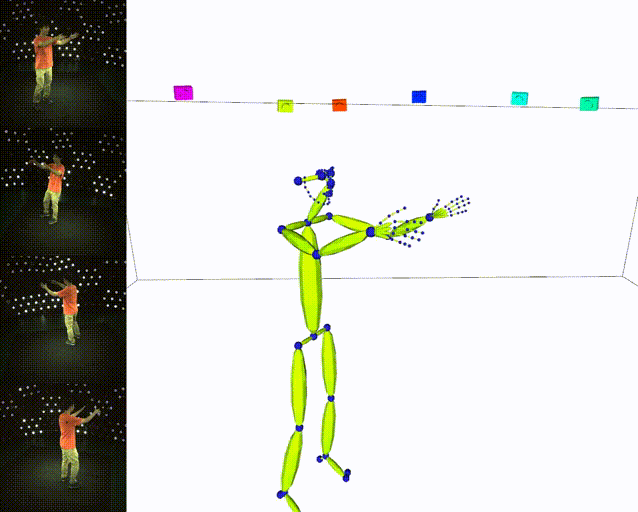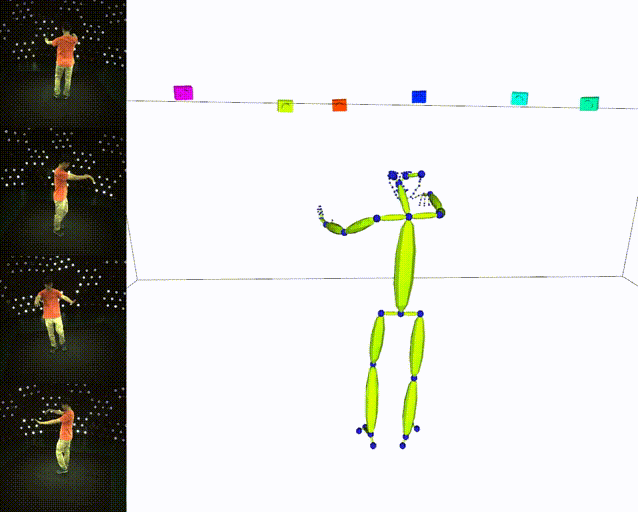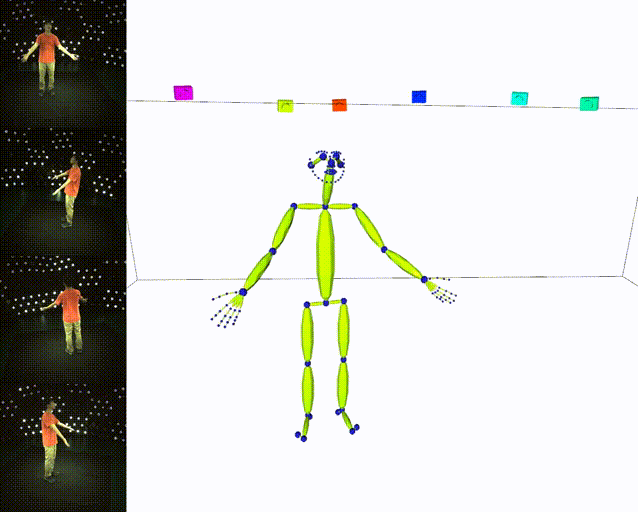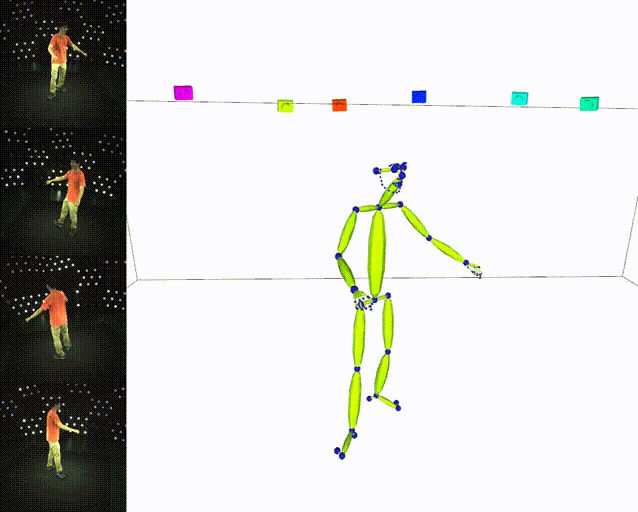 |
 |
Installation
1. Download SMPL models
To download the SMPL model go to this (male and female models) and this (gender neutral model) project website and register to get access to the downloads section. Place them as following:
data
└── smplx
├── J_regressor_body25.npy
└── smpl
├── SMPL_FEMALE.pkl
├── SMPL_MALE.pkl
└── SMPL_NEUTRAL.pkl
2. Requirements
- torch==1.4.0
- torchvision==0.5.0
- opencv-python
- pyrender: for visualization
- chumpy: for loading SMPL model
Some of python libraries can be found in requirements.txt. You can test different version of PyTorch.
Quick Start
We provide an example multiview dataset[dropbox][BaiduDisk(vg1z)]. After downloading the dataset, you can run the following example scripts.
data=path/to/data
out=path/to/output
# 0. extract the video to images
python3 scripts/preprocess/extract_video.py ${data}
# 1. example for skeleton reconstruction
python3 code/demo_mv1pmf_skel.py ${data} --out ${out} --vis_det --vis_repro --undis --sub_vis 1 7 13 19
# 2. example for SMPL reconstruction
python3 code/demo_mv1pmf_smpl.py ${data} --out ${out} --end 300 --vis_smpl --undis --sub_vis 1 7 13 19
Not Quick Start
0. Prepare Your Own Dataset
zju-ls-feng
├── extri.yml
├── intri.yml
└── videos
├── 1.mp4
├── 2.mp4
├── ...
├── 8.mp4
└── 9.mp4
The input videos are placed in videos/.
Here intri.yml and extri.yml store the camera intrinsici and extrinsic parameters. For example, if the name of a video is 1.mp4, then there must exist K_1, dist_1 in intri.yml, and R_1((3, 1), rotation vector of camera), T_1(3, 1) in extri.yml. The file format is following OpenCV format.
1. Run OpenPose
data=path/to/data
out=path/to/output
python3 scripts/preprocess/extract_video.py ${data} --openpose <openpose_path>
2. Run the code
# 1. example for skeleton reconstruction
python3 code/demo_mv1pmf_skel.py ${data} --out ${out} --vis_det --vis_repro --undis --sub_vis 1 7 13 19
# 2. example for SMPL reconstruction
python3 code/demo_mv1pmf_smpl.py ${data} --out ${out} --end 300 --vis_smpl --undis --sub_vis 1 7 13 19
--vis_det: visualize the detection--vis_repro: visualize the reprojection--undis: use to undistort the images--sub_vis: use to specify the views to visualize. If not set, the code will use all views--vis_smpl: use to render the SMPL mesh to images.--start, --end: control the begin and end number of frames.
3. Output
The results are saved in json format.
<output_root>
├── keypoints3d
│ ├── 000000.json
│ └── xxxxxx.json
└── smpl
├── 000000.jpg
├── 000000.json
└── 000004.json
The data in keypoints3d/000000.json is a list, each element represents a human body.
{
'id': <id>,
'keypoints3d': [[x0, y0, z0, c0], [x1, y1, z0, c1], ..., [xn, yn, zn, cn]]
}
The data in smpl/000000.json is also a list, each element represents the SMPL parameters which is slightly different from official model.
{
"id": <id>,
"Rh": <(1, 3)>,
"Th": <(1, 3)>,
"poses": <(1, 72)>,
"shapes": <(1, 10)>
}
We set the first 3 dimensions of poses to zero, and add a new parameter Rh to represents the global oritentation, the vertices of SMPL model V = RX(theta, beta) + T.
Acknowledgements
Here are some great resources we benefit:
- SMPL models and layer is borrowed from MPII SMPL-X model.
- Some functions are borrowed from SPIN, VIBE, SMPLify-X
- Our project is similar with TotalCapture
We also would like to thank Wenduo Feng for the example data.
Contact
Please open an issue if you have any questions.
Citation
This project is the base of our other works: iMocap, Neural Body
@inproceedings{dong2020motion,
title={Motion capture from internet videos},
author={Dong, Junting and Shuai, Qing and Zhang, Yuanqing and Liu, Xian and Zhou, Xiaowei and Bao, Hujun},
booktitle={European Conference on Computer Vision},
pages={210--227},
year={2020},
organization={Springer}
}
@article{peng2020neural,
title={Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans},
author={Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, Xiaowei Zhou},
journal={arXiv preprint arXiv:2012.15838},
year={2020}
}